

딥러닝이 사용되는 분야는 다양하다.
그 중에서도 많은 딥러닝 모델들이
도전하는 분야가 바로 이미지 인식
분야다.
이미지 인식을 하기 위해서는 프레임을
이해하고 분해하고 해석할 수 있어야
한다. 딥러닝 이미지 인식분야에서 강력한
성능을 보이는 알고리즘이 바로
컨볼루션 신경망(Convolution Neural Network)이다.
컨볼루션 신경망(CNN)
컨볼루션 신경망은 입력된 이미지에서
특징을 한번더 추출해낸다. 특징을 추출하기
위해서 마스크(혹은 필터, 윈도, 커널이라고도 부른다.)
를 도입한다.
임의의 2x2 마스크를 만들고,
마스크에 임의의 가중치를 설정한다.
이미지를 기존 이미지에 순회하면서
적용하면 컨볼루션이라고 불리는
새로운 합성곱층이 만들어진다.
이 컨볼루션을 가지고 기존 이미지에서
더욱 정교한 특징량을 추출해낼 수 있게
된다.
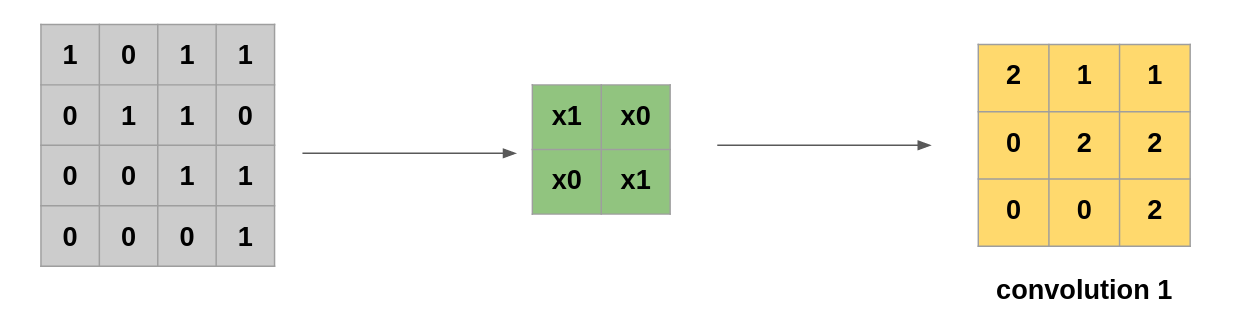
예를 들어 이미지 인식을 하고, 0,1값으로
이미지를 변환했다고 가정하자. 변환된
이미지 데이터의 값은 다음과 같다.

이제 임의의 가중치를 넣은 마스크를 하나
만들고, 위 테이블을 순회하면서 가중치 값을
계산한 새로운 테이블을 생산한다.

이 새로운 테이블이 컨볼루션 테이블이고,
이미지 특징량을 증폭시키는 매개채 역할을
하게 된다. 위 로직을 도식화 하면 다음과 같다.
Conv2D() 함수
keras 에서 컨볼루션 층을 생산하는 코드는 Conv2D()
함수를 사용한다. 먼저, 사용할 마스크의 갯수를 정의한다.
아래 코드에서는 32개의 마스크를 사용한다.
Kerner_size
kerner_size는 마스크의 크기를 지정한다. 아래 예시에서는
3x3 크기의 마스크를 사용한다.
input_shape
Dense() 함수를 사용에서 층을 추가하면 input_dim으로
입력층 값을 전달해야 한다. input_shape에서는
(행, 열, 컬러 또는 흑백) 값을 전달한다.
activation function
마지막으로 활성화 함수를 정의한다. 활성화 함수는 기울기
소실문제를 해결하기 위해 다음층으로 데이터를 넘길 때
사용하는 함수다.
|
1
|
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))
|
cs |
컨볼루션 층을 겹겹히 쌓으면서 이미지 인식 기능을
더 향상시킨다.
맥스 풀링(Max Pooling)
CNN에서 구축한 컨볼루션 층으로
이미지 특질량을 추가해서 이미지 인식의
정확도는 올릴 수 있지만, 또 다른 문제가
도사리고 있다. 바로 용량의 문제다.
다량의 컨볼루션을 추가하는 과정에서
결과값의 용량이 커지게 되고, 이는
딥러닝 모델의 성능 저하로 이어지게
된다. 여기서 필요한 개념이
풀링(pooling)이다.
풀링은 말 그대로 샘플링의 한 과정이다.
풀링 중에서도 가장 많이 사용되는 개념이
맥스 풀링이다. 맥스 풀링은 정해진 구역
내에서 가장 큰 값만 다음 층으로 보내고,
나머지는 모두 버리는 과정이다.
만약, 다음 같은 이미지 데이터가 있다면,
맥스 풀링은 구역을 나누고, 각 구역에서
가장 큰 값만으로 새로운 테이블을
만든다.

크기를 줄이면서, 특징량을
추출할 수 있는 테이블을 만들어가는
과정이다. 즉 불필요한 정보를 버리면서
필요한 데이터를 간추린다.

keras에서 maxpooling을 지원하는 함수는
MaxPooling2D()함수다.
pool_size는 풀링창의 크기를 의미한다.
2로 정하면 전체 크기가 절반으로
줄어들게 된다.
|
1
|
model.add(MaxPooling2D(pool_size=2)
|
cs |
드롭아웃(Drop Out)
딥러닝 신경망에서 조심해야 하는 것
중 하나가 바로, 과적합의 문제다.
과적합에 대해서 이해하고 싶다면
다음 글을 참고하길 바란다.
딥러닝 과적합 문제 해결하기(feat 광석 판별하기)
과적합(Overfitting)이란? 과적합은 특정 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터를 적용 하면 정확도를 높이지 못하는 현상을 의미한다. 과적합
incomeplus.tistory.com
학습 데이터셋에서는 높은 정확도를 보이는
모델이라도, 실제 테스트 환경에서는 정확도가
낮아지는 현상이 발생한다. 과적합 문제를
해결하기 위해 테스트 데이터와 학습 데이터를
구분해서 모델링을 하는 방법도 있지만,
간단하게 드롭아웃을 사용할 수 있다.
드롭아웃(Drop Out)은 은닉층에 배치된 노드 중
일부를 임의로 Off 하는 방식이다. 랜덤하게
노드들을 Off하면서 학습데이터에 지나치게
치중된 모델이 되지 않게 하는 것이다.
keras에서는 Dropout을 다음처럼 구현한다.
Dropout()함수가 받는 인자는 Off할
노드의 %이다. 절반의 노드를 Off하고 싶다면
0.5를 인자로 전달하면 된다.
|
1
|
model.add(Dropout(0.5)
|
cs |
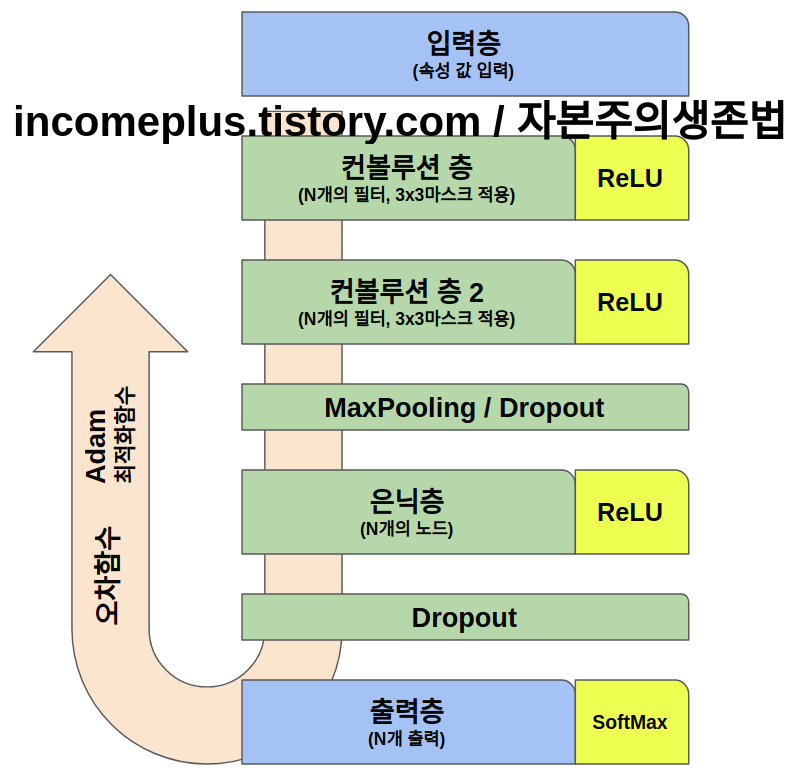
CNN 신경망 딥러닝 구동 순서를 전체적으로
보면 다음과 같다. 먼저 입력층에서
입력을 받아 컨볼루션층으로 보낸다.
컨볼루션 층에서는 마스크를 적용해서,
컨볼루션을 만들어 다음 층으로 보낸다.
크기를 조절하기 위해 MaxPooling()과
과적합을 해소하기 위해 Dropout()을
사용해서 다음 층으로 보낸다.
은닉층에서는 N개에 노드에서 입력값을
받아서 다음 층으로 보낸다.과적합을
피하기 위해서 Dropout() 함수를
사용한다.
출력층에서는 0,1의 특징을 도드라지게
하는 softmax를 활성화 함수로 사용하여
출력값을 뽑아낸다.
오차함수를 사용해서 예측값과 실제값의
오차를 계산하고, Adam() 최적화 함수를
사용해서 가중치w와 바이어스b를 새로
추정하는 작업을 반복하며 모델의
정확도를 올리고 오차를 줄이는 작업을
진행하는 것이다.
딥러닝 실전 예제
CNN 을 코드로 구현해보면 다음과 같다.
딥러닝 모델링을 위한 라이브러리들을 호출한다.
넘파이와 tensorflow에 일정한 랜덤값을 전달하기
위한 seed값을 설정한다.
손글씨 데이터를 MNIST에서 로드해서
학습셋과 테스트셋으로 구분한다.
이미지 데이터를 28x28 2차원 배열을
만들어서 실수형으로 변환한다. 색상은
흑백으로 설정한다. 또한 255를
나눠서 RGB값을 0과 1사이의 값으로
변환한다.
결과값 Y는 0과1로 구성된 길이 10의 1차원 배열로
변환한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.callbacks import ModelCheckpoint, EarlyStopping
import matplotlib.pyplot as plt
import numpy
import os
import tensorflow as tf
# seed 값 설정합니다.
seed = 0
numpy.random.seed(seed)
tf.compat.v1.set_random_seed(seed)
# MNIST 데이터 불러옵니다.
(X_train, Y_train), (X_test, Y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32')/255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32')/255
Y_train = np_utils.to_categorical(Y_train, 10)
Y_test = np_utils.to_categorical(Y_test, 10)
|
cs |
먼저 모델을 생성한다.
컨볼루션 층을 만든다. 32개의 필터를 가지고,
마스크 사이즈는 3x3으로 설정한다.
입력층에서 들어오는 입력값을
28x28 2차 행렬로 받는다. 색상은
흑백(1)이다. 컬러는 (3)을 주면 된다.
활성화 함수는 ReLU를 사용한다.
두번째 컨볼루션 층을 추가한다.
마스크 크기는 3x3으로 설정한다.
활성화 함수는 ReLU로 설정한다.
모델의 크기를 최적화 하기 위해
MaxPooling을 사용한다. 최적화할
크기는 기존 모델의 절반이다.
과적합 문제를 피하기 위해
Dropout()을 사용한다. 랜덤하게
Off할 노드는 25%로 설정한다.
2차원 데이터를 1차원 데이터로
변환하기 위해 Flatten()함수를
사용한다.
128개의 노드를 가진 은닉층을
추가한다. 활성화 함수는 ReLU를
사용한다.
과적합 문제를 피하기 위해
Dropout() 함수로 최종적으로 사용한다.
출력층은 노드 10개를 출력한다.
활성화 함수는 softmax함수를 사용한다.
이항 분류가 아닌 다항분류에서
0과 1의 특징을 두드러지게 하기 위한
함수다.
|
1
2
3
4
5
6
7
8
9
10
11
|
# 컨볼루션 신경망 설정합니다.
model = Sequential()
model.add(Conv2D(32, kernel_size=(3,3), input_shape=(28,28,1), activation='relu'))
model.add(Conv2D(64, (3,3), activation='relu'))
model.add(MaxPooling2D(pool_size=2))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
|
cs |
모델 학습을 실행한다.
오차함수는 categorical_crossentropy()를 사용한다.
최적화 함수는 Adam()함수를 사용한다.
테스트셋의 오차를 기준으로
모델의 정확도가 개선되지 않으면,
학습은 조기 중단된다.
모델을 실행한다.
에포크는 100회 반복되고,
batch_size는 200번으로 한번에
입력되는 샘플데이터는 200개다.
model.evaluate(Xtest, Ytest)로
결과값을 출력한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 모델 실행 환경 설정합니다.
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
# 모델 개선이 되지 않으면 학습을 중단한다.
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=10)
# 모델을 실행한다.
model.fit(X_train, Y_train, validation_data=(X_test, Y_test), epochs=100, batch_size=200, verbose=1, callbacks=[early_stopping_callback])
# 결과값을 출력한다.
print("\n Test Accuracy : %.4f" %(model.evaluate(X_test, Y_test)[1]))
|
cs |
더 읽을거리
딥러닝 머신러닝 차이, 머신러닝 딥러닝
머신러닝 딥러닝 차이 알파고가 대한민국을 초토화 시킨지 5년이 지났다. 실생활에도 인공지능이 많이 들어 왔고, 무수히 쌓여가는 데이터들을 기반으로 한 새로운 사업들이 계속 등장하고 있
incomeplus.tistory.com
딥러닝 실제 모델 만드는 방법 딥러닝 코드 구현해보기 이항 분류 keras 모듈 이용하기 (feat 인디
1. 데이터 : 피마 인디언 당뇨병 발생 유무 2. 문제형태 : 이항분류(Binary Classification) 3. 코드 구현 keras 모듈을 호출한다. tf.compat.v1.disable_eager_execution()는 tensorflow 버전 호환 문제를 해결..
incomeplus.tistory.com
딥러닝 손글씨 예측 모델 만들어보기 (feat 데이터정규화)
딥러닝 손글씨 인식하기 딥러닝을 공부하면 가장 유명한 도전과제가 손글씨를 인식하는 것이다. 컴퓨터가 사람이 쓴 글을 읽고 의미를 데이터화 하기 위해서 필수적인 과정이다. 손글씨를 이해
incomeplus.tistory.com
'Programming > MachineLearning' 카테고리의 다른 글
| 머신러닝 지도학습 비지도 학습 딥러닝 강화학습 차이점 아직도 모름? (0) | 2021.12.17 |
|---|---|
| 딥러닝 순환 신경망 RNN 10분 만에 이해하기 (0) | 2021.12.17 |
| 딥러닝 손글씨 예측 모델 만들어보기 (feat 데이터정규화) (0) | 2021.12.16 |
| 딥러닝 수치를 예측해보자 (feat 선형 회귀 분석) (0) | 2021.12.16 |
| 딥러닝 최적의 모델결과 뽑아내기 (feat 와인 데이터) (0) | 2021.12.16 |
| 딥러닝 데이터가 부족할 때 해결하는 방법 K겹 교차 검증이란? (feat 광석 돌 구분 예제 사용) (0) | 2021.12.16 |




댓글