

다중 분류 문제
0과 1 결과값 중 하나를 선택하는 문제가
아닌, 3개 이상의 결과값을 예측하는 모델을
다중 분류(Mulit Classification)이라 한다.
원-핫 코딩(one-hot-coding)
결과값에 문자열이 포함되어 있다면 이를
0과1로 구성된 숫자로 변경해주는 작업이
필요하다.
사이킷 런 라이브러리의 LabelEncoder()함수를
사용해서 원핫코딩 작업을 진행한다. 예를 들어
결과값이 'a', 'b', 'c' 3개의 값이 있다고 가정하자.
결과값을 다음과 같이 변경하는 것이다.
a => 1 => [1, 0, 0]
b => 2 => [0, 1, 0]
c => 3 => [0, 0, 1]
소프트맥스 활성화 함수(softmax)
입력층에서 받은 데이터는 1보다 큰 수로 이루어져
있다. 우리는 원핫 코딩을 통해 1,0으로 이루어진
리스트로 만들어서 결과값을 예측한다.
여기서 필요한 것이 소프트맥스 활성화 함수다.
소프트맥스는 합계가 1인 형태로 변환시켜준다.
즉, 큰 값은 두드러지게 나타나고 작은 값은 더
작아지도록 만들어, 원핫코딩이 원활하게 되도록
도와주는 활성화 함수다.
실전 예제
1. 데이터 : 아이리스 품종. csv
2. 활성화함수 : ReLU, softmax
3. 최적화함수 : Adam
4. 오차함수 : categorical_crossentropy
# 데이터 로딩
pands를 이용해서 데이터를 불러온다.
데이터의 양식을 확인해본다. 속성과
샘플값이 어떤지, 결과값(클래스)는 어떤
값을 가지고 있는지 확인한다.
데이터를 보면 Iris-setosa/ Iris-virginica 로
결과값이 다른 것을 확인할 수 있다. 총 샘플은
150개가 포함되어 있으며 속성값은
sepal_length, sepal_width, petal_length, petal_width
4개 칼럼으로 분류했다.
|
1
2
3
|
import pandas as pd
df = pd.read_csv('./dataset/iris.csv', names=["sepal_length", "sepal_width", "petal_length", "petal_width", "species"])
print(df)
|
cs |

# 데이터값 시각화하여 사전검증
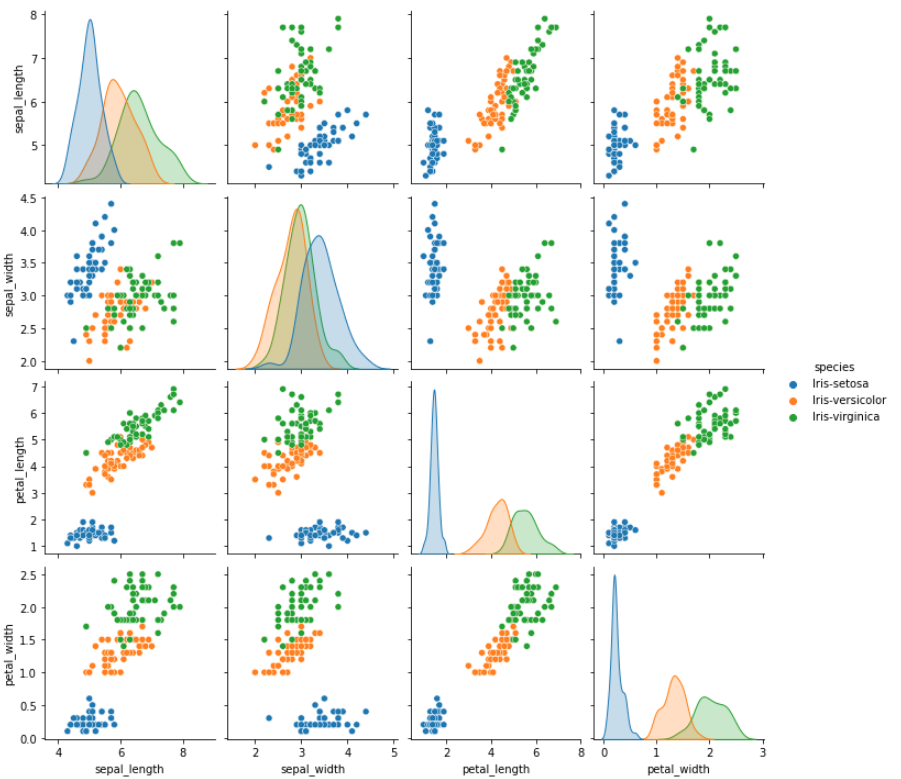
이제 matplotlib 라이브러리를 사용한다.
데이터를 결과값(클래스)에 따라서 어떤
분포도를 가지고 있는지를 확인해본다.
딥러닝 모델을 설계하고 실행하기 이전에,
먼저 데이터의 분포가 명확히 구분되어야
학습과 예측이 용이하기 때문이다.
그래프를 그려보면, 결과값에 따라서 명확히
구분되는 것을 확인할 수 있다. 특히 line-setosa의
품종은 다른 종들에 비해 더 두드러진 특지을
보이고 있다.
|
1
2
3
4
5
|
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df, hue="species")
plt.show()
|
cs |
# 데이터셋 구성
데이터셋에 pandas에서 불러온 데이터를
입력한다. X에는 속성값을 넣고, Y에는
결과값(클래스)를 입력한다.
|
1
2
3
|
dataset = df.values
X = dataset[:, 0:4].astype(float)
Y_obj = dataset[:, 4]
|
cs |
# 데이터셋 전처리
사이킷런 라이브러리에서 LabelEncoder()를
호출한다. 클래스(결과값)이 문자열인 경우에
숫자 형태로 변환해주는 함수다. 즉 꽃 종류가
문자열 형태에서 [1,2,3,4] 형태로 변환해준다.
결과값을 출력해보면 3개의 품종이 0, 1, 2형태로
변환된 것을 확인할 수 있다. 문자열을 숫자형태로
변환한 후에야 활성화함수 softmax()를 사용할 수
있기 때문이다.
|
1
2
3
4
5
|
from sklearn.preprocessing import LabelEncoder
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
|
cs |

# 데이터 전처리 2
이제 keras 라이브러리에서 np_utils 를 호출한다.
up_utils.to_categorical() 함수를 사용하는 것은
0,1,2형태의 수를 [0, 0, 1] 형태로 0과 1로 이루어진
배열로 변환해준다.
결과값을 출력해보면 이제 활성화 함수를 사용하기에
적합한 클래스(결과값)을 얻은 것을 확인할 수 있다.
|
1
2
3
|
from keras.utils import np_utils
Y_encoded=np_utils.to_categorical(Y)
print(Y_encoded)
|
cs |

# 딥러닝 모델 설계
모델을 구현하는 단계다.
Sequential()로 모델을 생성한다.
16개의 노드, 4개의 속성을 입력층으로 정하고,
다음층으로 보내는 활성화함수는 ReLU를 사용한다.
출력층에서는 노드를 3개로 정하고 활성화함수로
0과 1 사이의 특징을 도드라지게 하는 softmax()함수를
사용한다.
|
1
2
3
|
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
|
cs |
# 모델 컴파일
생성한 모델을 컴파일한다.
오차 함수는 categorical_crossentropy()를 사용한다.
최적화 함수는 Adam을 사용한다.
metrics를 정확도로 설정하여 컴파일을 진행한다.
|
1
2
3
|
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
|
cs |
컴파일한 모델을 실행한다.
epocs는 50을 줘서 모든 샘플이 50번 반복되게 한다.
batch_size는 1을 준다. 즉 한번 모델이 실행될 때
1개의 샘플을 집어넣어서 모델을 학습시킨다.
|
1
|
model.fit(X, Y_encoded, epochs=50, batch_size=1)
|
cs |
# 출력값 확인
출력값을 확인한다.
출력값은 model.evaluate()함수를 사용한다.
속성값과 결과값을 인자로 받아서 결과값을
출력한다.
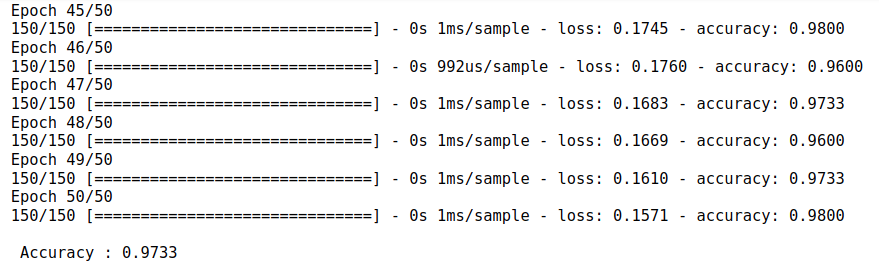
결과값을 확인해보면 epocs가 50번 돌아갔고,
오차는 점점 줄어들고, 정확도는 점점 올라가는
것을 확인할 수 있다.
최종적으로 학습데이터를 가지고 아이리스 품종을
분류하는 모델은 97.33%의 정확도로 3개의 품종을
분류해내는데 성공했다.
|
1
|
print("\n Accuracy : %.4f" % (model.evaluate(X, Y_encoded)[1]))
|
cs |
더 읽을거리
딥러닝 머신러닝 차이, 머신러닝 딥러닝
머신러닝 딥러닝 차이 알파고가 대한민국을 초토화 시킨지 5년이 지났다. 실생활에도 인공지능이 많이 들어 왔고, 무수히 쌓여가는 데이터들을 기반으로 한 새로운 사업들이 계속 등장하고 있
incomeplus.tistory.com
딥러닝 핵심 개념 신경망 10분만에 이해하기
인간의 신경망 작동 인간의 뇌는 약 1000억개의 뉴런으로 구성된다. 뉴런 사이에는 시냅스라는 연결부위가 존재한다. 신경 말단에서 자극을 받으면 시냅스에서 화학물질이 분비되고, 전위 변화
incomeplus.tistory.com
딥러닝 오차 역전파 10분만에 이해하기
딥러닝 오차 역전파 딥러닝은 학습데이터를 가지고 예측결과를 추론하는 알고리즘이다. 입력값은 기울기 a와 절편 b값이다. 딥러닝은 실제데이터와 차이는 부분을 오차로 규정하고, 가중치와
incomeplus.tistory.com
딥러닝의 층 구조 딥러닝을 배워보자
더보기 딥러닝 기본 구조 신경망 딥러닝의 구조는 크게 3부분으로 나뉘어져 있다. 1. 입력 부분 2. 분석 부분 3. 출력 부분 마지막으로 모델을 만들고 난 후, 컴파일을 하는 부분으로 구성된다. 층
incomeplus.tistory.com
딥러닝 로지스틱 회귀 알고리즘 10분만에 이해하기
선형회귀분석과 다르게, 참과 거짓만을 분별해야 하는 모델이 필요하다. 우리는 이때 로지스틱 회귀 분석 알고리즘을 이용하게 된다. 로지스틱 회귀 분석 참, 거짓을 구분하는 알고리즘이 로지
incomeplus.tistory.com
'Programming > MachineLearning' 카테고리의 다른 글
| 딥러닝 최적의 모델결과 뽑아내기 (feat 와인 데이터) (0) | 2021.12.16 |
|---|---|
| 딥러닝 데이터가 부족할 때 해결하는 방법 K겹 교차 검증이란? (feat 광석 돌 구분 예제 사용) (0) | 2021.12.16 |
| 딥러닝 과적합 문제 해결하기(feat 광석 판별하기) (0) | 2021.12.16 |
| 딥러닝 실제 모델 만드는 방법 딥러닝 코드 구현해보기 이항 분류 keras 모듈 이용하기 (feat 인디언 당뇨병 문제) (0) | 2021.12.15 |
| 딥러닝 오차 역전파 10분만에 이해하기 (0) | 2021.12.15 |
| 딥러닝 핵심 개념 신경망 10분만에 이해하기 (0) | 2021.12.15 |




댓글